CheckMag | Ingen GPU, inga problem. Att vara värd för din egen LLM är oändligt mycket roligare än de censurerade erbjudandena från de stora aktörerna och fungerar förvånansvärt bra.

Vad som egentligen händer med dina data när du ställer en fråga till en AI är det i stort sett ingen som vet, men vad som än händer med dem är de definitivt inte dina längre.
Vid sidan av bild och videogenerering, om du är angelägen om att experimentera med Large Language Models (LLM), men inte vill lämna över dina data till big tech, är det förvånansvärt enkelt att vara värd för din egen och har flera fördelar jämfört med de stora aktörerna.
Först och främst, oavsett vad du väljer att göra med det, förblir all din data under din kontroll, vilket, om du inte är angelägen om att lämna över dina data till Mechahitler, är ett omedelbart plus. Du får också använda i stort sett vilken modell du vill, oavsett om det är Deepseek, Gemma2 eller GPT, med den extra fördelen att kunna använda versioner som inte begränsar de typer av frågor du kastar in i den.
KoboldCPP är ett lättanvänt, enda exekverbart AI-textgenereringsverktyg som är utformat för att köra GGUF och GGML Large Language Models. Det stöder både GPU och CPU och kan fungera som en specialiserad backend för AI-berättande och chatt. KoboldCPP kan laddas ner från GitHub här och är tillgänglig för Windows, Linux, Mac eller Docker.
Hosting i en container gör det trivialt att exponera LLM till varje enhet i ditt nätverk, och det finns förbyggda mallar för de viktigaste plattformarna, inklusive Unraid och TrueNAS. Samma sak kan uppnås med andra installationer så länge du lägger till nödvändiga regler i din brandvägg.
Komma igång
När du har bestämt dig för vilken plattform du ska välja måste du ta reda på vilken modell du ska använda. Kramande ansikte är det bästa stället att leta efter modeller, och de måste vara i GGUF-format.
Om du planerar att vara värd för D&D-scenarier kommer du definitivt att vilja ha en ocensurerad modell, annars kommer LLM i slutändan att vägra att skada någon av karaktärerna och kan generera oönskat resultat.
Vissa modeller, till exempel Deepseek och Claudehar en benägenhet att "tänka", vilket i princip spottar ut hela tankeprocessen i din fråga. Detta kan vara OK med en GPU som gör tunga lyft, men utan en saktar processen ner avsevärt. Du måste experimentera med modeller för att hitta en som fungerar för dig, men Gemma2 är ett bra ställe att börja på.
Hitta sidan med filer och kopiera webbadressen som länkar till GGUF-filen. Många modeller har flera storlekar, så du måste välja en som passar inom gränserna för ditt tillgängliga RAM-minne.
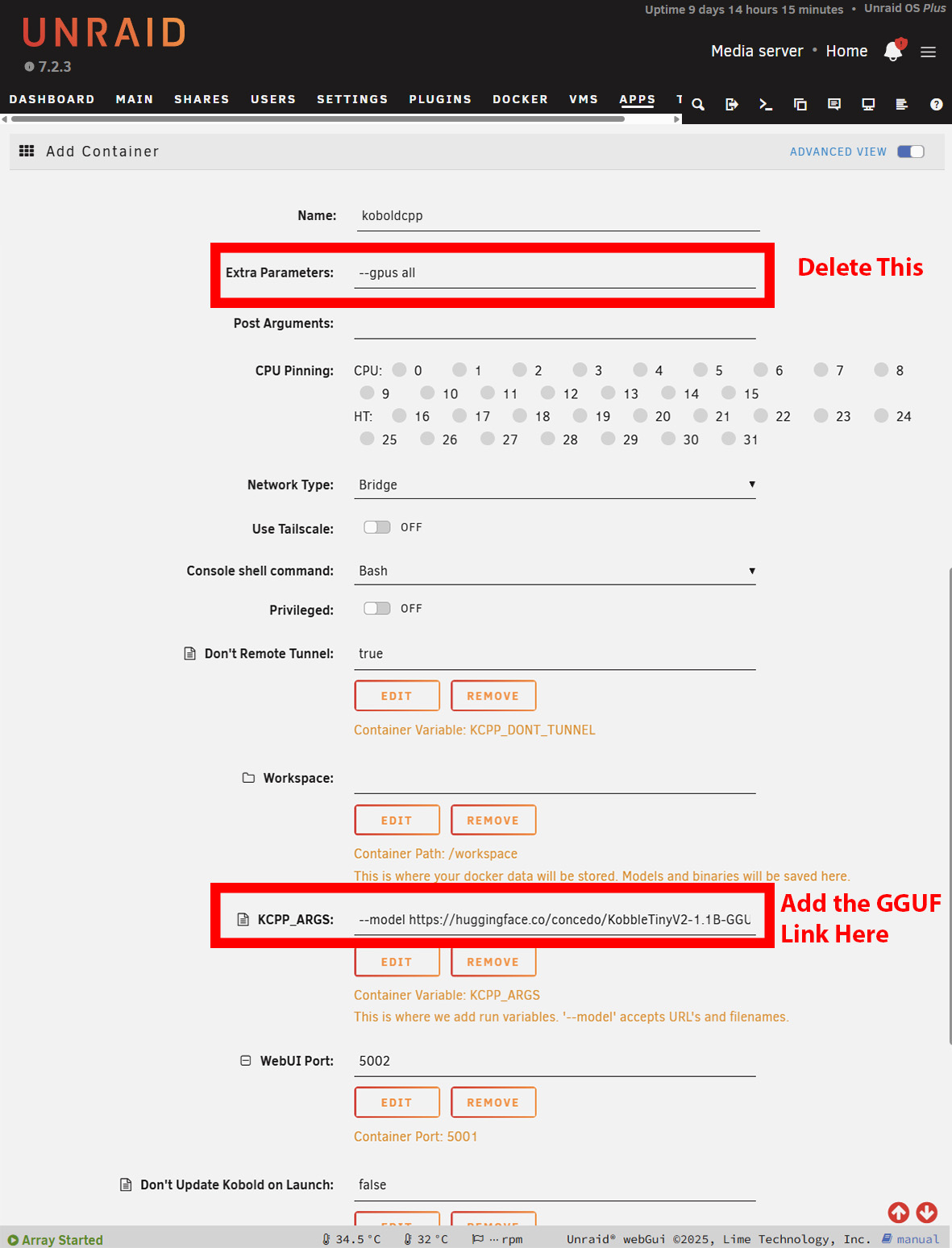
Installationen på Windows är i stort sett densamma. Du måste dock ladda ner NoCUDA version om du använder utan en GPU. Det kan ta ett tag att starta, eftersom KoboldCPP kommer att ladda ner modellen innan du presenterar gränssnittet. På Windows är detta uppenbart, men på Unraid eller TrueNAS måste du öppna loggarna för att se hur nedladdningen fortskrider. På Unraid kan du behöva öka docker-containerns tillgängliga lagring beroende på hur stor din valda modell är.
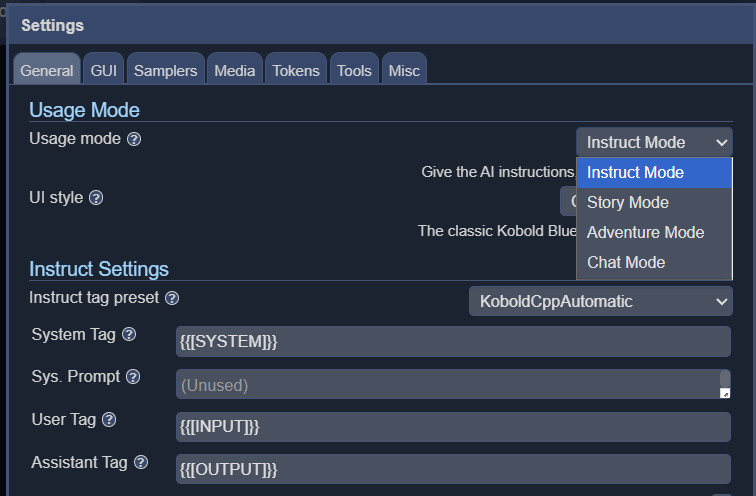
KoboldCPP erbjuder 4 olika gränssnittslägen, inklusive instruera, berättelse, chatt och äventyr.
Även om det inte är den snabbaste på något sätt, genereras texten något långsammare än den genomsnittliga läshastigheten. Perfekt användbar för D&D-scenarier när du kör på en 16-kärnig AMD 5950x(Finns på Amazon) och kommer sannolikt att köra snabbare på modernare CPU: er. Ju fler kärnor du kan kasta på det, desto bättre, och en anständig mängd RAM-minne gör att du kan köra större modeller, även om du borde vara bra med 16 GB. Storleken och typen av modell kommer också att ha en betydande inverkan på generationshastigheten, och att välja en mer lättviktig modell kan öka den totala hastigheten avsevärt.
För den bästa upplevelsen är det självklart optimalt att köra stora språkmodeller med en GPU, men om du är angelägen om att försöka vara värd för dina egna, kringgå begränsningarna eller dataintegritetsimplikationerna av ChatGPT, Claude eller Gemini, behöver du ingen snygg hårdvara för att komma igång och du kan fortfarande få en anständig upplevelse.
Källa(n)

