Ett överraskande språk slår engelska och kinesiska i LLM-tester, enligt ny akademisk studie
En ny flerspråkig studie som utvärderar hur stora språkmodeller hanterar långa dokument har gett oväntad information: Polska, inte engelska eller kinesiska, uppvisar den högsta noggrannheten när kontextfönstren sträcker sig till 64 000 tokens och mer. Resultaten kommer från OneRuler benchmark som introducerades i ett COLM 2025-dokumentdär 26 språk testades i olika uppgifter för hämtning och aggregering.
Forskarna jämförde modellnoggrannhet vid flera kontextlängder och fann ett tydligt skifte när sekvenserna blev längre. Enligt resultatdiagrammet (på sidan 6) leder polska alla språk med en genomsnittlig noggrannhet på 88% vid långa kontextskalor. Engelska faller till sjätte plats och kinesiska hamnar bland de fyra sämsta.
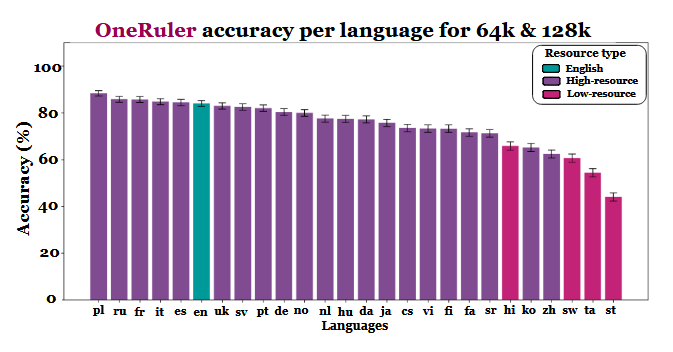
Studien antyder att skillnaderna kan vara kopplade till tokeniseringseffektivitet och skillnader i skriptbaserade system snarare än till mängden träningsdata. Språk som använder latinbaserade skript - som polska, franska och spanska - presterade genomgående bättre än de som använder logografiska eller abugida skrivsystem. Kinesiska, koreanska, tamilska och andra språk uppvisade endast måttlig träffsäkerhet även i kortare sammanhang (och träffsäkerheten försämrades ytterligare när sekvenserna blev längre). Denna totala 180 av förväntade rankningar är intressant, eftersom de flesta allmänt distribuerade LLM:erna främst är tränade på engelskspråkiga dataset. Resultaten i artikeln visar dock att när modellerna måste söka, återkalla eller sammanfatta information som ligger djupt begravd i långa dokument, prioriteras språkets strukturella aspekter framför datasetets utbredning.
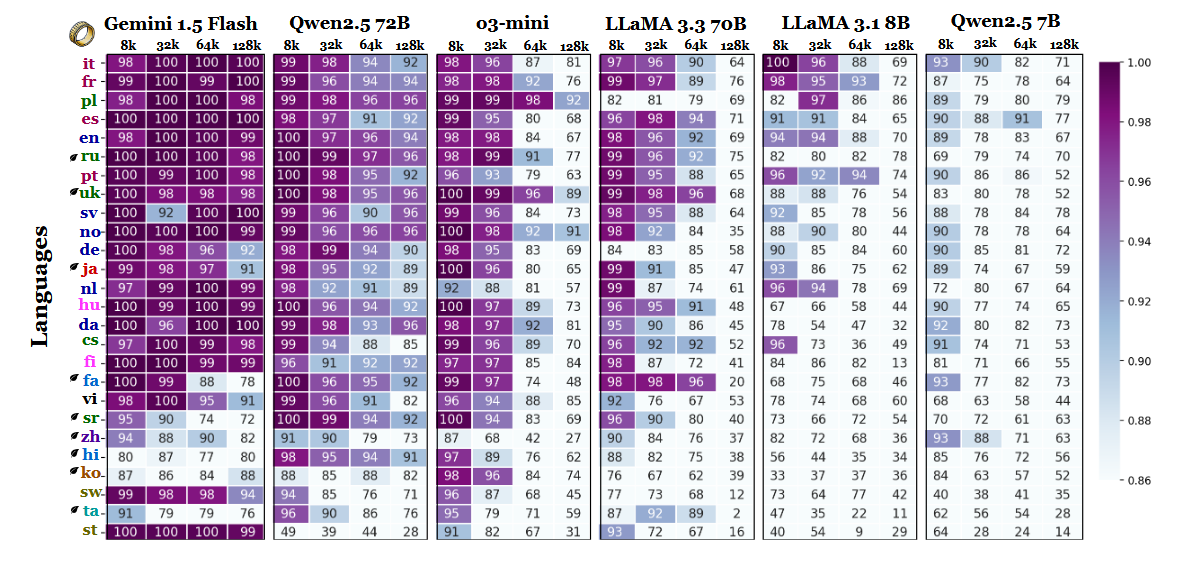
Andra resultat i jämförelsen stöder också denna tolkning. Prestandagapet mellan de starkaste och svagaste språken växer kraftigt när sammanhanget expanderar - från 11% vid 8 000 tokens till 34% vid 128 000 tokens. En annan detalj från studien visar hur känsliga dessa tester kan vara för små förändringar i instruktionerna. Om man till exempel bara låter modellen svara "ingen" om en målsträng saknas, så minskar träffsäkerheten på engelska med 32% vid 128 000 tokens, vilket syns på sidan 2.
Även om riktmärket också jämför modellfamiljer innebär resultaten att utvärdering av långa kontexter inte enbart kan baseras på engelska tester och att generaliseringar av prestanda mellan olika språk kan vara missvisande om man bortser från skript- och tokeniseringseffekter. När kontextfönstren blir större blir språkliga skillnader viktigare, inte mindre - och engelskans dominans i LLM-benchmarks kanske inte längre är representativ när sekvenslängderna klättrar upp i tiotusentals.
Källa(n)
En linjal för att mäta dem alla: Benchmarking av flerspråkiga språkmodeller med långa kontexter vid COLM 2025
Utvalda bilden av Zulfugar Karimov på Unsplash

