Detta praktiska verktyg med öppen källkod hämtar text från vad som helst - till och med videor och bilder
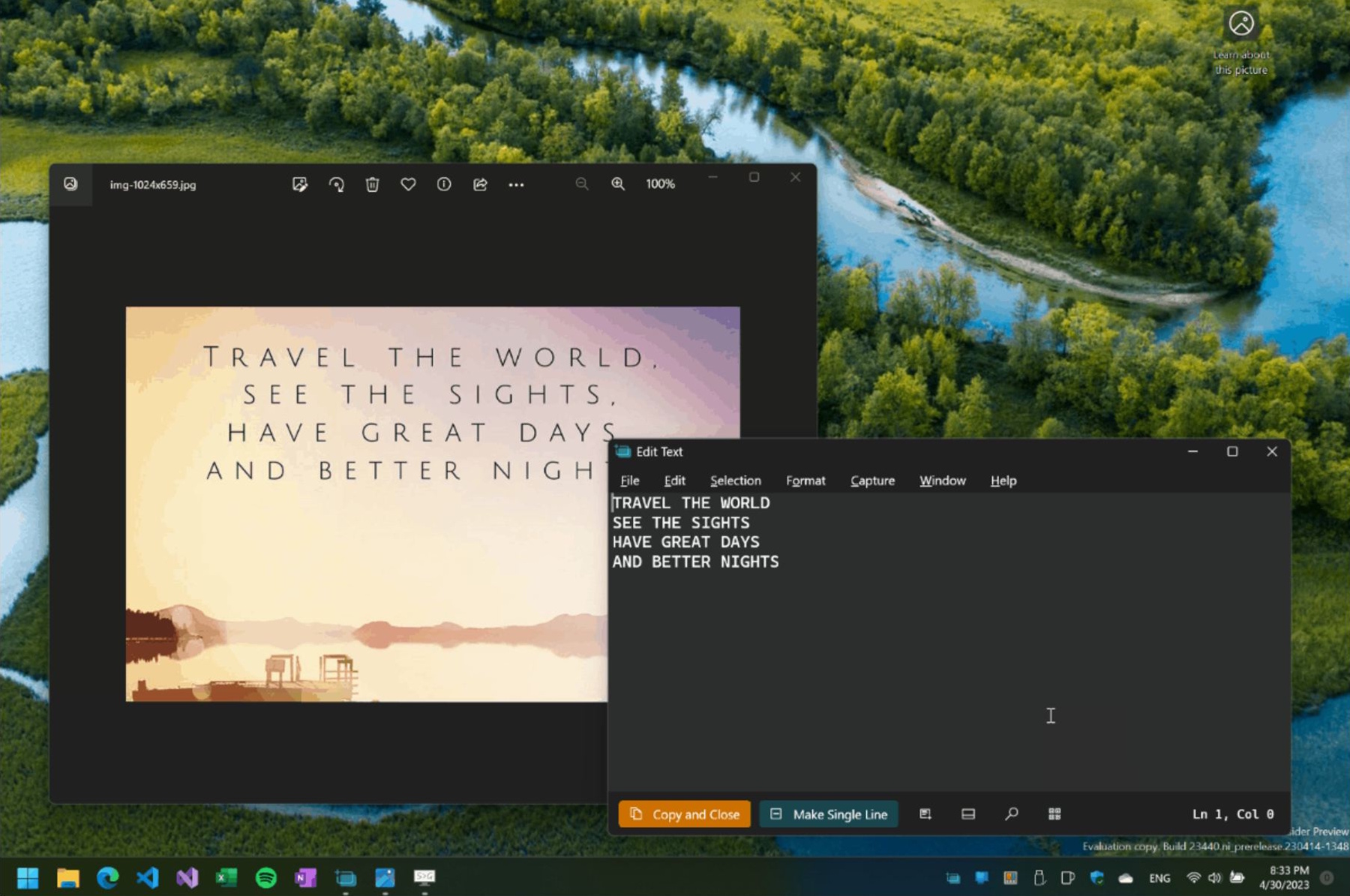
Känner du igen problemet? De flesta PDF-filer låter dig kopiera text utan problem. Men då och då stöter man på en PDF som uppenbarligen inte alls har skapats från ett textdokument - den har genererats från skannade bilder, trots att innehållet är helt och hållet text. I dessa fall kan du inte markera eller kopiera något om du inte använder extra verktyg. Det är frustrerande.
Ett annat exempel: Jag tittar på en video om de bästa RC-crawlers (fjärrstyrda bilar som är specialbyggda för att ta sig fram i extremt tuff terräng) i en viss prisklass eftersom mitt barn gillar dem. Modellnamnen visas i videon, men de finns ingenstans som valbar text i beskrivningen.
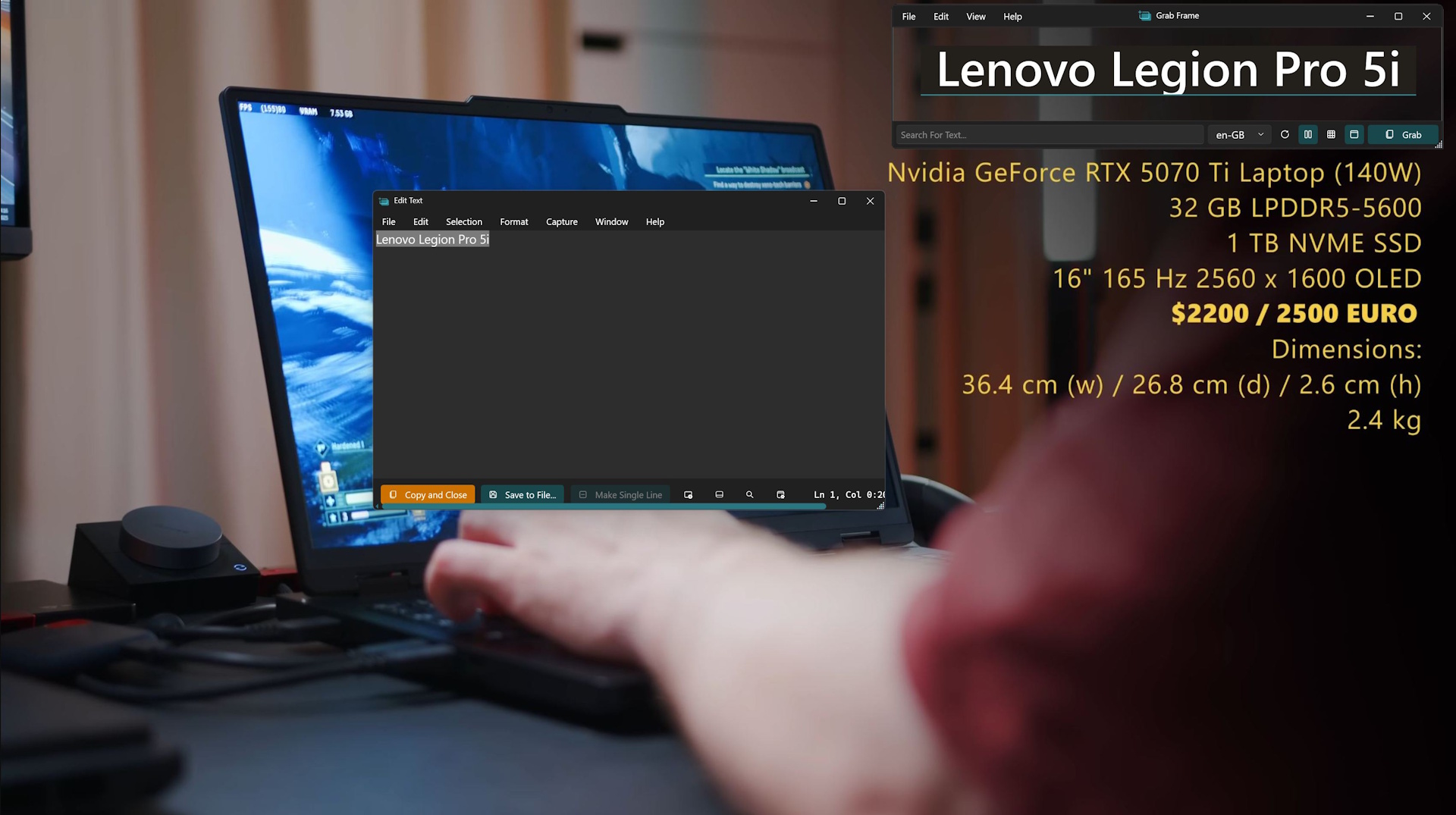
Det är där Text Grab kommer in i bilden: Detta verktyg med öppen källkod finns tillgängligt på Github för Windows x86- och ARM64-datorer, och det gör exakt vad jag önskar att jag hade i dessa situationer: det extraherar text från bilder, videor, fotobaserade PDF-filer - i princip från allt som visas på din skärm.
Att använda det kunde inte vara enklare. Appen fungerar som ett vanligt skärmdumpverktyg. Du tar en bild av hela skärmen eller bara ett valt område, och Text Grab känner omedelbart igen all text i den bilden och kopierar den till ditt urklipp. Precis som med andra skärmdumpverktyg kan du ställa in dina egna snabbtangenter för att ta tag i hela skärmen eller specifika regioner.
Trots att appen bara är 74 MB erbjuder den flera sätt att fånga text. Du kan skanna hela skärmen, rita en ram runt ett mindre område eller till och med klicka direkt på ett enda ord. Om du vill kan verktyget automatiskt öppna Notepad med den extraherade texten redo för redigering.
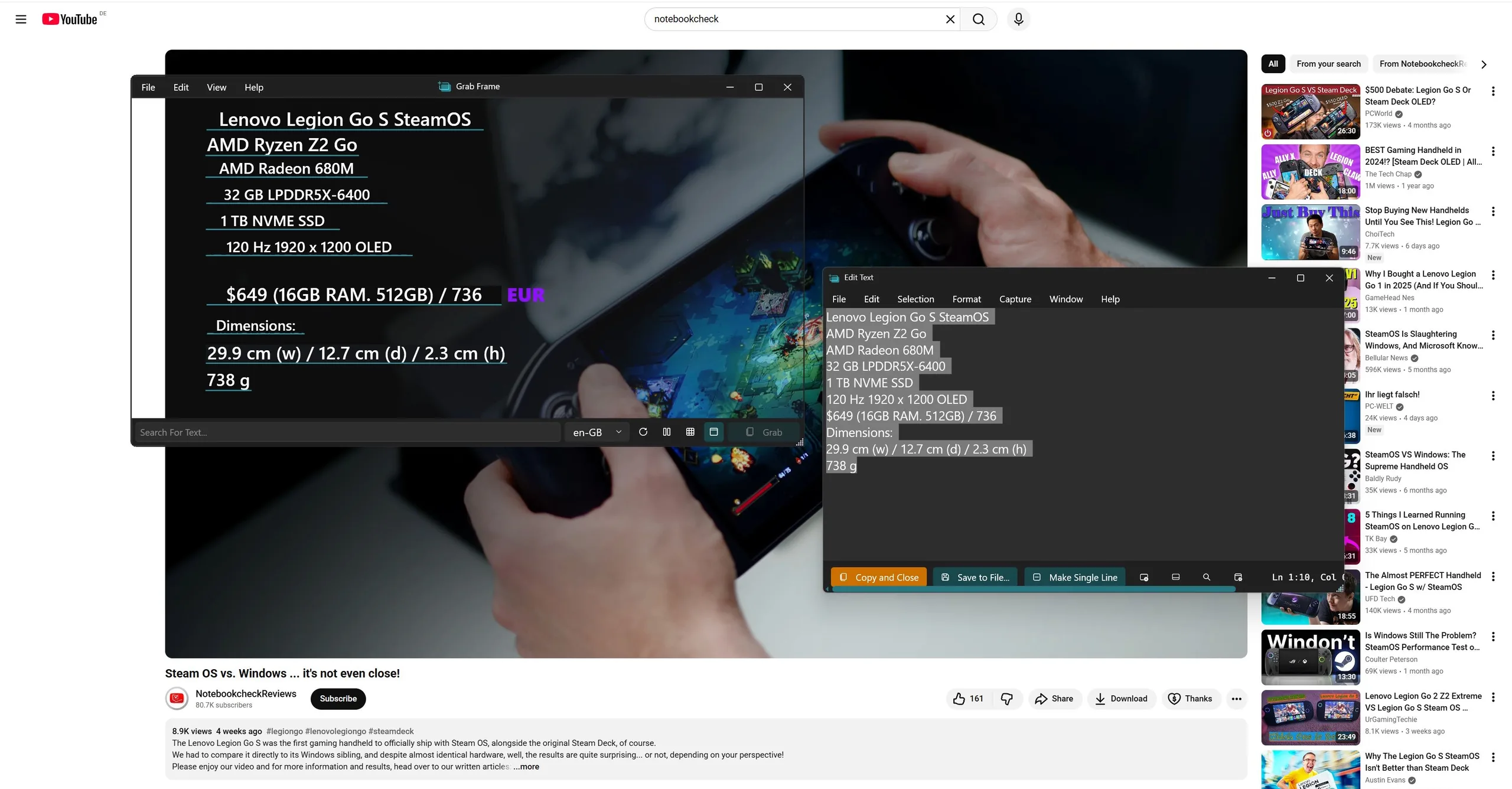
Så här fungerar det: Bakom kulisserna tar appen en skärmdump och skickar den till OCR-motorn (Optical Character Recognition) som är inbyggd i Windows API. Allt körs lokalt.
Verktyget är i allmänhet mycket exakt, lättviktigt och helt öppen källkod. Det är dock inte perfekt. Jag har haft några fall där det har läst något fel, men den inbyggda redigeraren som dyker upp automatiskt gör snabba korrigeringar enkla.

